Un sistema visual para comprender, comunicar y construir sentido
Vivimos en un mundo saturado de códigos, símbolos, interfaces e instrucciones. Comprenderlo requiere habilidades lingüísticas, contextuales y culturales que no siempre están disponibles para todos. ¿Qué ocurre cuando una persona no puede leer, no habla, o interpreta de forma diferente los signos convencionales?
PictoNet es un sistema generativo de comunicación visual diseñado para personas con necesidades complejas de comunicación (NCC), como adultos autistas o personas con discapacidad intelectual. A partir de frases escritas, genera pictogramas vectoriales1 que representan acciones, situaciones o intenciones. Su propósito es doble: facilitar la autonomía comunicativa de las personas y crear un lenguaje visual accesible, abierto y evolutivo.
La tarea de traducir palabras a imágenes no es sencilla, está en el corazón y origen del diseño visual como el problema de la interpretación, la integración y la síntesis. PictoNet propone una nueva forma de construir sentido, articulando elementos de la lingüística computacional, la inteligencia artificial2 y el diseño en su sentido amplio. La idea de fondo no es nueva: Otto Neurath ya había propuesto un lenguaje visual universal con Isotype3, inspirado a su vez por los sueños de Leibniz y Frege de una lingua universalis lógica4. Más recientemente, el enfoque NSM (Natural Semantic Metalanguage)5 ha demostrado que es posible reducir el lenguaje humano a un conjunto reducido de conceptos universales comprensibles por cualquier cultura. Tomo esto como base para fundamentar este intento aparentemente universalista pero respetuoso de lo local y situado.
PictoNet se inspira en esta tradición, pero la desplaza desde el plano lógico-lingüístico hacia el plano visual, apoyándose en la teoría del blending conceptual 6 para construir imágenes que sintetizan en integran significados dispersos. Diferentes notas musicales pueden sonar como un acorde. En esta metáfora la caja de resonancia es la mente humana. Este sistema no busca ilustrar literalmente una frase, sino de crear una imagen mental que exprese su intención, su foco, y sus relaciones internas. Desde allí, se traduce a una forma visual precisa, limpia y manipulable. Este pequeño detalle hace que la imagen deba ajustarse al contexto cultural donde opera.
Este sistema busca ser algo más que una herramienta: una gramática visual compartida, que cada persona pueda adaptar y expandir según su contexto. Un punto de partida para recuperar la soberanía sobre el lenguaje visual en un mundo que, cada vez más, delega la mediación del sentido a sistemas opacos.
¿Para qué sirve PictoNet?
PictoNet se concibe como una herramienta para amplificar la autonomía de personas neurodivergentes y facilitar la comprensión del entorno a través de representaciones visuales generadas dinámicamente. Al ofrecer una traducción visual explícita de acciones, intenciones o instrucciones, PictoNet puede emplearse en múltiples contextos:
| Necesidad comunicativa | Ejemplo concreto | Cómo ayuda PictoNet |
|---|---|---|
| Comprender una instrucción | “Saca la leche del refrigerador” | Traduce la frase en una imagen con acción, objeto y contexto |
| Realizar una tarea secuencial | “Poner la tetera y esperar que hierva” | Genera pictogramas con temporalidad y pasos diferenciados |
| Formular una pregunta | “¿Dónde está mi mochila?” | Representa estructura interrogativa y foco de búsqueda |
| Comprender una situación social | “Están esperando turno en la fila” | Visualiza relaciones espaciales y roles sociales |
| Expresar una emoción o estado | “Estoy confundido” | Asocia expresión facial, postura corporal y etiqueta textual |
| Comunicar una urgencia | “Me duele el estómago” | Presenta señal visual clara y alerta diferenciada |
| Comprender un proceso institucional | “Solicitar hora médica en el centro de salud” | Descompone el procedimiento en etapas visuales comprensibles |
| Participar en una actividad grupal | “Hoy hay reunión de equipo a las 3 PM” | Representa la situación, las personas y el tiempo contextual |
| Seguir reglas de comportamiento | “En el ascensor no se habla fuerte” | Representa norma, espacio y modulación de conducta |
| Acceder a trámites o servicios | “Descargar certificado de nacimiento desde la web” | Genera pictograma secuencial con elementos tecnológicos |
Cada uno de estos ejemplos podría resolverse mediante imágenes preexistentes. Pero PictoNet no se basa en un repertorio fijo, sino en un modelo generativo capaz de producir pictogramas a partir de combinaciones lingüísticas nuevas o específicas. Esto permite adaptarse a contextos cambiantes, a variaciones culturales y a estilos personales de comprensión.
La salida visual se produce en formato SVG (Scalable Vector Graphics), que permite una representación gráfica clara y ajustable a diferentes tamaños, y también contiene una estructura interna que puede ser manipulada programáticamente o manualmente7.
PictoNet, por tanto, no entrega una imagen cerrada, sino una propuesta visual abierta: comprensible por máquinas, interpretable por humanos y editable según criterios personales, clínicos o culturales.
Tres niveles
El proyecto global, inscrito en mi tesis doctoral (basada en la práctica) “MediaFranca: A pictogram-based communication tool for self-determination in individuals with complex communication needs (CCN)” se organiza en tres escalas interconectadas. Cada nivel aborda una dimensión distinta del problema comunicativo, desde la representación visual básica hasta la construcción colectiva del sentido. Estos niveles no se definen desde la técnica sino que expresan posturas epistémicas y éticas sobre el lenguaje, la autonomía y la colaboración.
Nivel 1: Motor generativo de pictogramas PictoNet (Texto → SVG)
El primer nivel de PictoNet constituye su núcleo operativo. Se trata de un sistema que, dado un texto de entrada (por ejemplo: “regar las plantas”), genera un pictograma vectorial que representa visualmente esa acción. Esta imagen no es una ilustración cualquiera sino un pictograma que busca ser accesible cognitivamente: sigue una sintaxis gráfica explícita y está construida sobre una “espina semántica” que permite identificar y modificar los elementos relevantes, así como establecer una relación (ojalá epiyectiva) con el texto de entrada que lo generó.
La motivación principal en este nivel es facilitar la autonomía comunicativa de personas con necesidades complejas de comunicación, permitiendo acceder al mundo simbólico mediante un lenguaje visual comprensible y personalizable. Al mismo tiempo, este nivel inaugura un nuevo campo de exploración: la composición visual programática como base para una gramática del diseño universal.
Este motor combina diversas capas de procesamiento semántico y visual, descritas en la siguiente tabla:
Pipeline generativo de PictoNet
| Fase | Tipo de modelo | Función principal | Modelos de referencia |
|---|---|---|---|
| 1. Clasificación pragmática | Clasificador semántico | Determina la intención comunicativa (volitivo, asertivo, afectivo, interrogativo, etc.) | JointBERT8, RoBERTa-base9 |
| 2. Extracción de entidades visuales | NER visual | Identifica entidades representables gráficamente (acciones, objetos, lugares) | spaCy NER10, mT511 |
| 3. Blending conceptual | Composición semántica | Fusiona elementos en una imagen coherente (ej. “calentar comida en microondas”) | ConceptNet12, TARS13 |
| 4. Selección de foco y layout | Estructura discursiva | Establece jerarquía entre elementos visuales y su disposición | BART14, FLAN-T515 |
| 5. Atributos gráficos | Mapeo semiótico | Asocia propiedades semánticas con atributos visuales (color, animación, forma) | Sketch-RNN16, CSS generator17 |
| 6. Composición SVG | Generador gráfico | Produce un SVG estructurado con plantilla y grilla coherente | CodeT5+18, SVG-VAE19 |
Este pipeline (muy tentativo aún) busca hacer que la “caja negra” sea una caja transparente, donde cada módulo pueda ser interpretado, ajustado o reemplazado. La documentación transparente del modelo es una prioridad: se busca que cualquier persona (usuario, ingeniero, terapeuta o diseñador) pueda entender cómo se construye un pictograma, intervenir en su diseño, o contribuir a mejorar el sistema.
Desde el punto de vista teórico, este modelo se inspira en la teoría del blending conceptual, que postula que las imágenes mentales emergen de la integración de múltiples espacios conceptuales. PictoNet traduce este proceso al plano visual, generando una imagen que sintetiza estructura, foco e intención de una frase.
Entonces, el objetivo de PictoNet como apuesta técnica y semiótica es crear un core engine20 generativo, modular y abierto que permita representar visualmente el mundo desde el lenguaje, contribuyendo a una comunicación más equitativa, explícita y comprensible.
Nivel 2: Sistema personalizable con soberanía semiótica (2026)
El segundo nivel de PictoNet responde a una pregunta fundamental: ¿quién decide cómo se ve y qué significa una imagen?
Si el primer nivel provee un modelo funcional para generar pictogramas, este segundo nivel habilita a cada persona o institución a intervenir activamente en ese proceso. A través de una interfaz editable, el usuario puede modificar, reinterpretar o refinar los pictogramas generados según su contexto, estilo cognitivo o necesidades culturales. Cada instancia del sistema mantiene un espacio visual propio, donde se almacenan preferencias, configuraciones semióticas y variantes gráficas.
Esquema de interfaz “round trip” donde se puede ajustar tanto el lado izquierdo (orden, estilo, re-prompt del ícono) y el lado derecho a nivel de nodos y dibujo directo.
Esta arquitectura distribuida responde a una motivación ética: restituir a las personas el control sobre su lenguaje visual. En lugar de delegar completamente en una infraestructura algorítmica centralizada estándar. PictoNet ofrece una modalidad de trabajo human-in-the-loop, donde cada usuario puede editar, guardar y retroalimentar el sistema21.
Este enfoque se alinea con la idea de convivencialidad desarrollada por Ivan Illich22, quien planteaba que las herramientas no deben superar la capacidad de sus usuarios para comprenderlas y gobernarlas. En el contexto actual —dominado por plataformas de suscripción, modelos opacos y algoritmos que operan como cajas negras— PictoNet plantea una alternativa: una infraestructura semiótica autogestionable, donde las extensiones cognitivas no se alquilan, se construyen.
A través de este sistema, cada persona puede:
- Generar pictogramas con base en su estilo preferido
- Definir su repertorio visual, incluyendo variantes culturales o personales
- Ajustar atributos como color, nivel de detalle, animación o composición
- Exportar sus pictogramas o reentrenar el modelo localmente con sus ediciones
Estas funciones además de promover la accesibilidad, promueven también la expresión humana. No se trata únicamente de comunicar “lo mínimo necesario”, sino de dar forma visual a formas propias de habitar el mundo.
| Configuración visual | Ejemplo de personalización |
|---|---|
| Nivel de detalle | Más esquemático o más descriptivo |
| Estilo de trazo | Lineal, geométrico, figurativo |
| Uso del color | Normativo (rojo = peligro), emocional o neutral |
| Composición visual | Horizontal, vertical, secuencial |
| Animación | Indicación de repetición, afecto o cambio |
| Número de entidades por imagen | Síntesis vs. complejidad expresiva |
El lenguaje visual es aquí entendido como un sistema vivo, que se negocia, se adapta y se transforma. Esta capa propone una forma de soberanía semiótica: que cada quien pueda editar su gramática visual, no desde el capricho individual, sino desde la necesidad de construir sentido en sus propios términos.
PictoNet, en este nivel, no es una aplicación. Es una plataforma convivencial: una herramienta que respeta la inteligencia del usuario y amplía su capacidad de decir con imágenes.
Nivel 3: Plataforma colaborativa y aprendizaje federado (2027)
En su tercera capa, PictoNet se proyecta como una infraestructura distribuida que articula múltiples instancias del sistema, cada una con su propia configuración visual, pero conectadas a través de un lenguaje técnico común. La motivación aquí no es técnica —ya no se trata de generar imágenes ni de editarlas—, sino de construir una economía semiótica abierta y colaborativa, donde las contribuciones de cada usuario puedan fortalecer colectivamente el modelo.
Este nivel se estructura sobre el principio de aprendizaje federado, una técnica de inteligencia artificial que permite entrenar modelos compartidos sin necesidad de centralizar los datos23. Cada interacción, cada corrección o variante visual que realiza el usuario puede ser encapsulada como una unidad significativa de ajuste —sin revelar información privada— y luego incorporada, si se valida, al modelo general.
Este enfoque parte de una intuición simple pero potente: la diversidad de interpretaciones visuales es un recurso, no un problema. Aprovechar esa diversidad requiere diseñar mecanismos de sincronización, curaduría y control de versiones que no borren las diferencias, sino que las integren de forma coherente.
| Componente del sistema | Mecanismo propuesto |
|---|---|
| Perfil pictográfico federado | Cada usuario/institución mantiene un stack local |
| Sincronización distribuida | Cambios locales se empaquetan como instrucciones |
| Curaduría distribuida | Validación automática, por pares o institucional |
| Historial trazable | Cada modificación tiene autor, fecha y justificación |
| Transparencia algorítmica | Código fuente documentado, legible y versionado |
| Interoperabilidad semántica | Estructuras compartidas usando JSON-LD y ontologías |
Este tipo de plataforma requiere una gobernanza técnica cuidada, donde el “centro” no sea un ente controlador, sino un nodo de ensamblaje que ejecuta entrenamientos globales, publica nuevas versiones y conserva todas las variantes locales. Las personas no entregan sus datos: contribuyen con conocimiento generado desde su propia forma de ver.
La ambición de esta capa no es sólo tecnológica. Apunta a imaginar una nueva economía de las inteligencias artificiales: una economía basada en colaboración, transparencia y responsabilidad compartida. Frente al modelo tecnofeudal24, donde los usuarios entregan trabajo cognitivo a cambio de servicios opacos, PictoNet propone una economía simbólica descentralizada, donde cada quien conserva el control sobre su lenguaje, su historia y sus contribuciones.
Aquí, la colaboración no es solo posible: es estructural. El código está en GitHub. La documentación es detallada y pormenorizada. El sistema acepta mejoras, pull-requests, reportes de error y extensiones conceptuales. Participar no es un privilegio técnico: es parte de la arquitectura del sistema.
PictoNet, en su forma más plena, es un común semiótico computacional: una herramienta pública, culturalmente sensible, gobernada colectivamente por quienes la usan y la hacen evolucionar.
Perfecto. Continuamos con la sección Ejemplos y funcionamiento interno, que ofrece una mirada concreta al sistema en acción. Aquí se pone en juego todo lo descrito previamente: la generación automática, la estructura del SVG, y las posibilidades de edición en una interfaz round-trip. Incluyo una descripción detallada del caso “hacer la cama”, basado en el ejemplo que entregaste a los ingenieros.
Ejemplos y funcionamiento interno
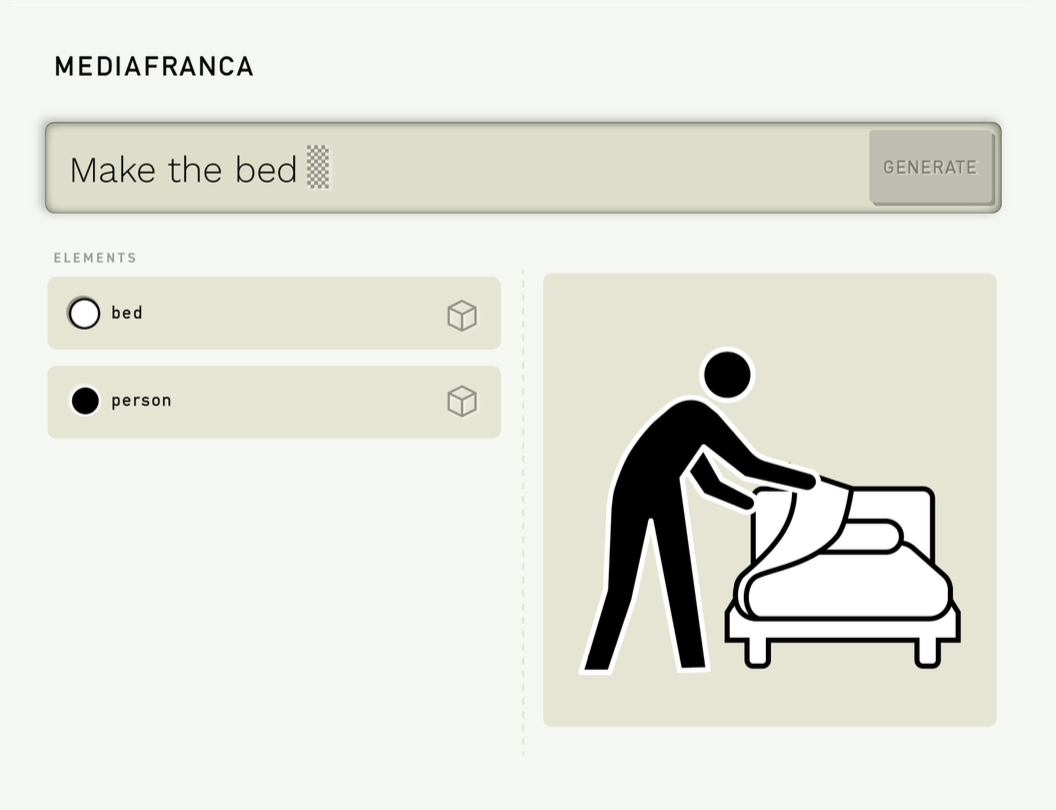
Para ilustrar cómo opera PictoNet, tomemos una frase sencilla: “hacer la cama”. Este enunciado activa una secuencia de operaciones dentro del pipeline generativo: se reconoce la intención (acción volitiva), se extraen entidades visuales (persona, cama, sábanas), se define el foco (acción), y se compone una imagen visual esquemática en formato SVG.
El resultado es un pictograma estructurado, con etiquetas que identifican cada elemento: bed, pillow, sheet, person, arm, body, etc. Cada parte está dibujada como un nodo independiente, editable y con estilo definido mediante CSS.

<?xml version="1.0" encoding="UTF-8"?>
<svg id="pictogram" xmlns="http://www.w3.org/2000/svg" version="1.1" viewBox="0 0 100 100">
<!-- Make the bed -->
<defs>
<style>
.f {
fill: #fff;
stroke: #000;
stroke-linejoin: square;
}
.k {
fill: #000;
stroke: #FFF;
stroke-linejoin: square;
}
</style>
</defs>
<g id="bed">
<path id="bed_frame" class="f" d="M86.6,66.1l6.7,10.9v7.1h-5.1v5.1c0,.9-.7,1.6-1.6,1.6h-2.3c-.9,0-1.6-.7-1.6-1.6v-5.1h-38.2v5.1c0,.9-.7,1.6-1.6,1.6h-2.3c-.9,0-1.6-.7-1.6-1.6v-5.1h-5.1v-7.1l6.7-10.9v-18.5c0-1.3,1.1-2.4,2.4-2.4h41.3c1.3,0,2.4,1.1,2.4,2.4v18.5h-.1Z"/>
<path id="matress" class="f" d="M85.9,78.6h-44.4c-3,0-5.4-2.4-5.4-5.4v-1.9c0-1.5.7-3,1.8-4l7.7-6.8c1-.9,2.3-1.4,3.6-1.4h29c1.3,0,2.6.5,3.6,1.4l7.7,6.8c1.2,1,1.8,2.5,1.8,4v1.9c0,3-2.4,5.4-5.4,5.4Z"/>
<path id="pillow" class="f" d="M52.2,53.5h22.4c2.3,0,4.1,1.8,4.1,4h0c0,2.2-1.8,4-4.1,4h-22.4c-2.3,0-4.1-1.8-4.1-4h0c0-2.2,1.8-4,4.1-4Z"/>
<path id="sheet" class="f" d="M50.6,39.6c2.1,1.3,15.3,5.5,15.3,5.5,0,0-1.3,9.6-3.9,12.5-6.3,7.1-17.2,8.3-20.7,10.2s-3.4,9.7.8,10.8c-7.6.3-6.9-8.9-4.2-11.3s7.9-6.7,10.7-11.7c4.1-7.4,2.3-13.8,2-16Z"/>
</g>
<g id="person">
<path id="arm" class="k" d="M29.9,37.5l4.2,7.8,6.7,3.7c1.1.6,1.5,2.1.7,3.2h0c-.6.8-1.7,1.1-2.6.7l-9.1-3.9-4.1-6.4"/>
<path id="body" class="k" d="M29,90.5l-4.9.2-5-35.6-3,18.9-4.2,17.1h-5l4.3-19.7.6-19.4c.2-2.1.2-3.2.6-5,0,0,.8-3.7,2-6.9s3.5-7.2,5.2-9.3l2.3-2.7c2.4-2.8,6.7-3.1,9.5-.7l2.1,1.8,7.6,9.2c.8.9,1.8,1.6,3,2l10,3c1.4.4,2.2,2,1.6,3.4h0c-.5,1.1-1.7,1.8-2.9,1.5l-13.7-3.3-9.1-7.5-4.9,7.5,4,45.5h0Z"/>
<circle id="head" class="k" cx="38.9" cy="19.9" r="5.5"/>
</g>
</svg>
Este archivo no es una ilustración cerrada. Es un documento visual estructurado y semántico: cada parte puede ser reescrita, reposicionada o reemplazada. El usuario puede, por ejemplo:
- Cambiar la posición de las manos para que parezca que estira las sábanas
- Reescribir el mini-prompt asociado a “bed” con una descripción más detallada
- Activar una animación leve que represente el movimiento de estirar
- Guardar esta variante como su forma preferida de expresar la acción
En la interfaz de PictoNet, esto se realiza a través de un sistema round-trip: cada pictograma puede ser examinado desde el lenguaje (orden, estilo, intención) o desde su forma gráfica (nodos, vectores, layout).
Este tipo de interacción ofrece un equilibrio entre autonomía visual y claridad técnica: el usuario no necesita saber código, pero el sistema está construido para que el código esté siempre disponible, legible y ajustable.
| Acción del usuario | Resultado en el sistema |
|---|---|
| Editar la forma de la cama | Actualiza el SVG y registra una nueva variante |
| Modificar el estilo del trazo | Cambia la configuración visual y afecta futuras generaciones |
| Cambiar el mini-prompt | Afecta la entrada semántica y reconstruye la imagen |
| Calificar el pictograma | Introduce feedback para el reentrenamiento |
| Compartir una versión | Puede ser validada y propuesta como estándar |
Cada pictograma, entonces, no es solo una imagen, sino una expresión singular de sentido visual que puede evolucionar, ser refinada, y alimentar el sistema general. PictoNet se convierte así en una cartografía abierta, donde cada imagen generada forma parte de una geografía común del lenguaje.
Y lo más importante: este flujo no se impone como estándar universal, sino que respeta y conserva las formas particulares de representación que cada persona o comunidad define como significativas.
¿Quién puede usar PictoNet?
PictoNet está pensado como una herramienta inclusiva, pero no restringida. Aunque su diseño parte de las necesidades comunicativas de personas neurodivergentes, su arquitectura flexible y su enfoque de diseño universal abren posibilidades para una amplia gama de usuarios.
A continuación, algunos perfiles y formas de uso:
| Perfil | Uso principal | Valor añadido |
|---|---|---|
| Adultos autistas o no hablantes | Generar imágenes para expresar necesidades o comprender rutinas | Comunicación autónoma sin depender de estructuras predefinidas |
| Cuidadores, familiares, docentes | Apoyar la organización del día, explicar tareas, construir rutinas | Personalización del lenguaje visual según la persona que acompaña |
| Terapeutas del lenguaje o TO | Crear materiales adaptados a objetivos terapéuticos | Ajuste de dificultad, foco y estilo para cada intervención |
| Diseñadores de servicios públicos | Mejorar accesibilidad cognitiva de entornos físicos y digitales | Producción de señalética adaptada culturalmente y por nivel cognitivo |
| Desarrolladores de software | Integrar PictoNet a apps, asistentes o interfaces multimodales | Acceso programático al motor generativo de pictogramas |
| Investigadores | Estudiar la semiótica visual, el blending conceptual o el lenguaje CAA | Posibilidad de observar patrones de representación y adaptación |
| Comunidades culturales | Construir repertorios visuales propios | Apropiación simbólica del lenguaje visual según códigos locales |
Lo importante es que PictoNet no exige conocimientos técnicos. Su interfaz está diseñada para que cualquier persona —sin escribir una línea de código— pueda generar imágenes, modificarlas y construir su propia “lengua visual”. Al mismo tiempo, quienes quieran intervenir a un nivel más profundo —desde ajustar el pipeline hasta contribuir con código— también pueden hacerlo.
El sistema propone así una doble entrada:
- Para usuarios sin conocimientos técnicos: una interfaz intuitiva, con edición visual, opciones semióticas y retroalimentación directa.
- Para usuarios técnicos o institucionales: acceso al motor generativo, posibilidad de reentrenar modelos, interoperabilidad con otros sistemas.
De este modo, PictoNet puede ser usado tanto por una madre que quiere ayudar a su hijo a estructurar su día, como por una universidad que desea investigar nuevas formas de interacción visual. Lo que se comparte entre ambos casos es la posibilidad de intervenir, ajustar y expandir el sistema según las necesidades y conocimientos propios.
PictoNet no entrega soluciones cerradas. Propone una herramienta abierta para construir soluciones propias, respetando las capacidades, lenguajes y contextos de cada quien.
Ética y enfoque
En el centro del proyecto mayor (MediaFranca) está la pregunta por el sentido: ¿cómo se construye sentido cuando no se comparte una lengua común?.
El proyecto nace de una preocupación concreta —la falta de accesibilidad comunicativa para muchas personas—, pero su alcance es más amplio. Lo que propone es una forma distinta de entender el diseño: no como entrega de soluciones, sino como construcción de condiciones para que cada persona pueda articular su mundo de forma explícita y compartible.
Esto implica una ética. Una que no se basa en proteger usuarios pasivos, sino en reconocer capacidades y habilitar agencia. Este proyecto trabaja desde y para el diseño con el sentido de:
- Tratar el lenguaje visual no como un producto, sino como una facultad compartida (patrimonio de la humanidad)
- Evitar el encierro algorítmico y la dependencia de plataformas cerradas
- Promover una cultura técnica donde las herramientas puedan ser comprendidas, editadas y compartidas
Este enfoque se opone a las lógicas de extracción de datos y control unidireccional que caracterizan a buena parte de las inteligencias artificiales contemporáneas. Frente a esa deriva tecnofeudal25, MediaFranca plantea un ecosistema convivencial y distribuido, donde los usuarios no son datos, sino autores.
En términos proyectuales, esto se traduce en decisiones específicas:
| Dimensión ética | Implementación en PictoNet |
|---|---|
| Transparencia | Código abierto, documentación pormenorizada, trazabilidad de cambios |
| Apropiabilidad | Edición directa del lenguaje visual, exportación de repertorios |
| Pluralismo semiótico | Admisión de variantes culturales, estilos y sintaxis visuales |
| Colaboración crítica | Plataforma abierta a contribuciones, pull requests, forks trazables |
| Respeto a la diversidad | Personalización semiótica por perfil, sin imponer un estándar universal |
| Responsabilidad distribuida | Validación descentralizada, historial de edición, curaduría por pares |
MediaFranca no impone cómo debe verse el mundo. Al contrario, ofrece herramientas para que cada quien diga cómo lo ve, cómo lo entiende y cómo desea expresarlo. Y el sistema, en cuanto andamiaje compartido (y heredero de todo el corpus estadístico) entregará aquello que hemos acordado es lo más entendible. Recordemos que el lenguaje es un fenómeno eminentemente social, inter-humano y que siempre apelará al instante original donde estamos cara a cara.
En esta lógica, el diseño ya no es una disciplina de producción simbólica, sino una práctica de hospitalidad: habilitar que otros habiten sus propios lenguajes con claridad, con poder y con derecho.
Participar y colaborar
PictoNet no es un producto terminado. Es una infraestructura en evolución, y necesita colaboradores con distintos saberes: desarrolladores, terapeutas, diseñadores, cuidadores, investigadores, activistas. Cualquiera que crea que el lenguaje —incluso el visual— debe ser compartido, explícito y editable.
Hay muchas formas de contribuir:
| Forma de colaboración | Qué implica |
|---|---|
| Sugerir mejoras al sistema | Enviar pull requests o abrir issues en el repositorio |
| Evaluar pictogramas generados | Comentar, calificar y corregir desde la interfaz visual |
| Proponer nuevos módulos | Añadir funciones al pipeline o extender ontologías |
| Construir repertorios locales | Diseñar lenguajes visuales adaptados a culturas o contextos |
| Traducir documentación | Hacer accesible el proyecto en múltiples lenguas |
| Usar PictoNet con propósito | Probar el sistema en situaciones reales, dar feedback |
El código está alojado en GitHub y se publica bajo una licencia Creative Commons Atribución 4.026, que permite su uso libre, siempre que se reconozca la fuente.
Además del código, se publicará una documentación extensa, que explica cómo usar, modificar y contribuir al sistema. Esto incluye:
- Esquemas del pipeline generativo
- Manuales de estilo visual
- Especificaciones técnicas del SVG
- Protocolos de validación semiótica
- Guías para creación de instancias personalizadas
Todo está pensado para facilitar una comunidad técnica y semiótica mundial, donde las diferencias no sean un obstáculo, sino una riqueza compartida.
Si quieres colaborar contáctame directamente.
- Scalable Vector Graphics, un formato editable y estructurado que permite representar imágenes con alta claridad y control semántico ↩
- En su sub-rama de máquinas de aprendizaje ↩
- Ver Neurath, O. International Picture Language. 1936 ↩
- Leibniz, G.W. Characteristica Universalis, Frege, G. Begriffsschrift, 1879 ↩
- Wierzbicka, A. (1996). Semantics: Primes and Universals. Oxford University Press ↩
- Fauconnier, G. & Turner, M. (2002). The Way We Think: Conceptual Blending and the Mind’s Hidden Complexities. Basic Books ↩
- Esto habilita tanto la interoperabilidad con otras plataformas como la posibilidad de ediciones finas por parte del usuario sin pérdida de semántica visual ↩
- JointBERT ↩
- RoBERTa-base ↩
- spaCy NER ↩
- mT5 ↩
- ConceptNet ↩
- TARS ↩
- BART ↩
- FLAN-T5 ↩
- Sketch-RNN ↩
- CSS generator ↩
- CodeT5+ ↩
- SVG-VAE ↩
- Como núcleo de lenguaje permitirá que otros servicios más sofisticados y complejos se apoyen en este motor pictográfico generativo, como por ejemplo interfaces XR, sistemas de proyección, head-up displays o agentes robóticos, entre otros. ↩
- La IA no tiene, ni debe tener, la última palabra. Recordemos que se trata de un sistema estadístico que no puede imponer patrones comunicativos, sólo generar propuestas estadísticamente viables. ↩
- Illich, I. (1973). Tools for Conviviality. Harper & Row ↩
- Kairouz, P. et al. (2021). Advances and Open Problems in Federated Learning. Foundations and Trends® in Machine Learning, 14(1–2), 1–210. ↩
- Morozov, E. (2022). It’s time to abandon the myth of Big Tech’s ‘free’ services. The Guardian. ↩
- Zuboff, S. (2019). The Age of Surveillance Capitalism. PublicAffairs; Varoufakis, Y. (2024). Technofeudalism: What Killed Capitalism. Vintage. ↩
- https://creativecommons.org/licenses/by/4.0/ ↩